硬件抽象层统一了硬件调用的接口。
gralloc
图形缓冲,用于保存图形的一段内存。图形缓冲运行在一个独立的进程.由它负责分配图形缓冲。 是一个独立的进程。gralloc对应的接口类
interface IAllocator {
allocate(BufferDescriptor descriptor, uint32_t count)
generates (Error error,
uint32_t stride,
vec<handle> buffers);
};
其中BufferDescriptor描述了申请的buffer的宽高格式等信息。count表示申请的缓冲区的个数。 IAllocator 的具体实现在pasthrough.cpp
……
extern "C" IAllocator* HIDL_FETCH_IAllocator(const char* /* name */) {
return GrallocLoader::load();
}
class GrallocLoader {
public:
static IAllocator* load() {
const hw_module_t* module = loadModule();
if (!module) {
return nullptr;
}
auto hal = createHal(module);
if (!hal) {
return nullptr;
}
return createAllocator(std::move(hal));
}
// load the gralloc module
static const hw_module_t* loadModule() {
const hw_module_t* module;
int error = hw_get_module(GRALLOC_HARDWARE_MODULE_ID, &module);
if (error) {
ALOGE("failed to get gralloc module");
return nullptr;
}
return module;
}
// create an AllocatorHal instance
static std::unique_ptr<hal::AllocatorHal> createHal(const hw_module_t* module) {
int major = getModuleMajorApiVersion(module);
switch (major) {
case 1: {
auto hal = std::make_unique<Gralloc1Hal>();
return hal->initWithModule(module) ? std::move(hal) : nullptr;
}
case 0: {
auto hal = std::make_unique<Gralloc0Hal>();
return hal->initWithModule(module) ? std::move(hal) : nullptr;
}
default:
ALOGE("unknown gralloc module major version %d", major);
return nullptr;
}
}
// create an IAllocator instance
static IAllocator* createAllocator(std::unique_ptr<hal::AllocatorHal> hal) {
auto allocator = std::make_unique<hal::Allocator>();
return allocator->init(std::move(hal)) ? allocator.release() : nullptr;
}
};
galloc 启动服务
int main() {
return defaultPassthroughServiceImplementation<IAllocator>(4);
}
分配图形缓冲流程
客户端向galloc请求分配图形缓冲。
Allocator.allocate
AllocatorImpl.allocateBuffers
Gralloc0HalImpl.allocateOneBuffer.alloc
gralloc_context_t.gralloc_alloc
gralloc.gralloc_alloc_buffer  通过getserice获取gralloc的服务mallocator 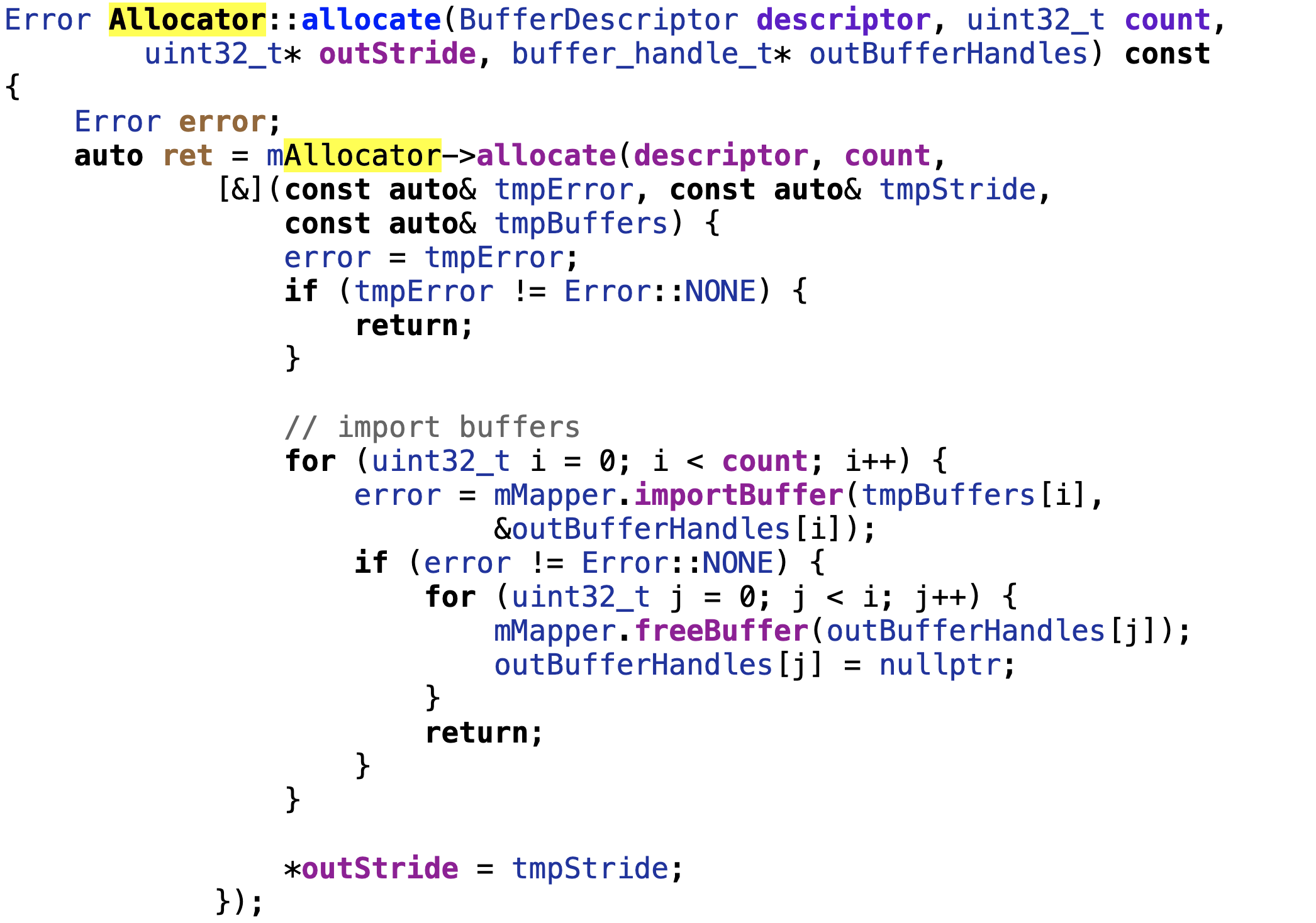 通过gralloc的代理服务mallocator调用allocate,向gralloc进程申请成功得到的缓冲通过outbufferhandles返回给调用者。
最终调用gralloc的gralloc_alloc_buffer分配内存缓冲
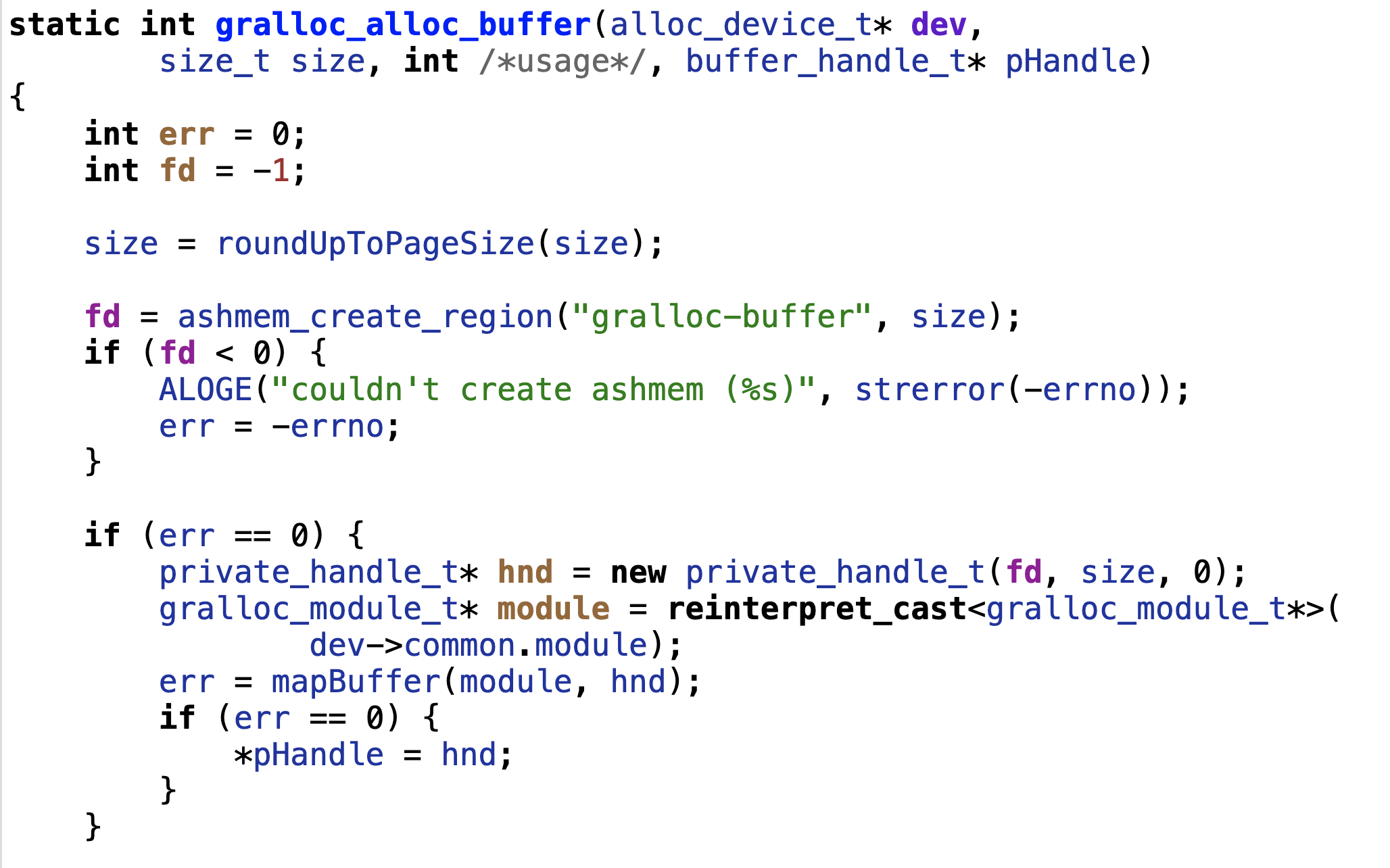 通过ashmem_create_region分配内存,最终将分配的内存的文件描述符以buffer_handle_t返回给客户端,客户端通过binder夸进程传输这个文件描述符,拿到文件描述符后就可以通过mmap操作得到缓冲地址。
通过ashmem_create_region分配内存,最终将分配的内存的文件描述符以buffer_handle_t返回给客户端,客户端通过binder夸进程传输这个文件描述符,拿到文件描述符后就可以通过mmap操作得到缓冲地址。
图像缓冲
分配的图像缓冲内存以graphicbuffer表示.创建graphicbuffer阶段初始化就会调用

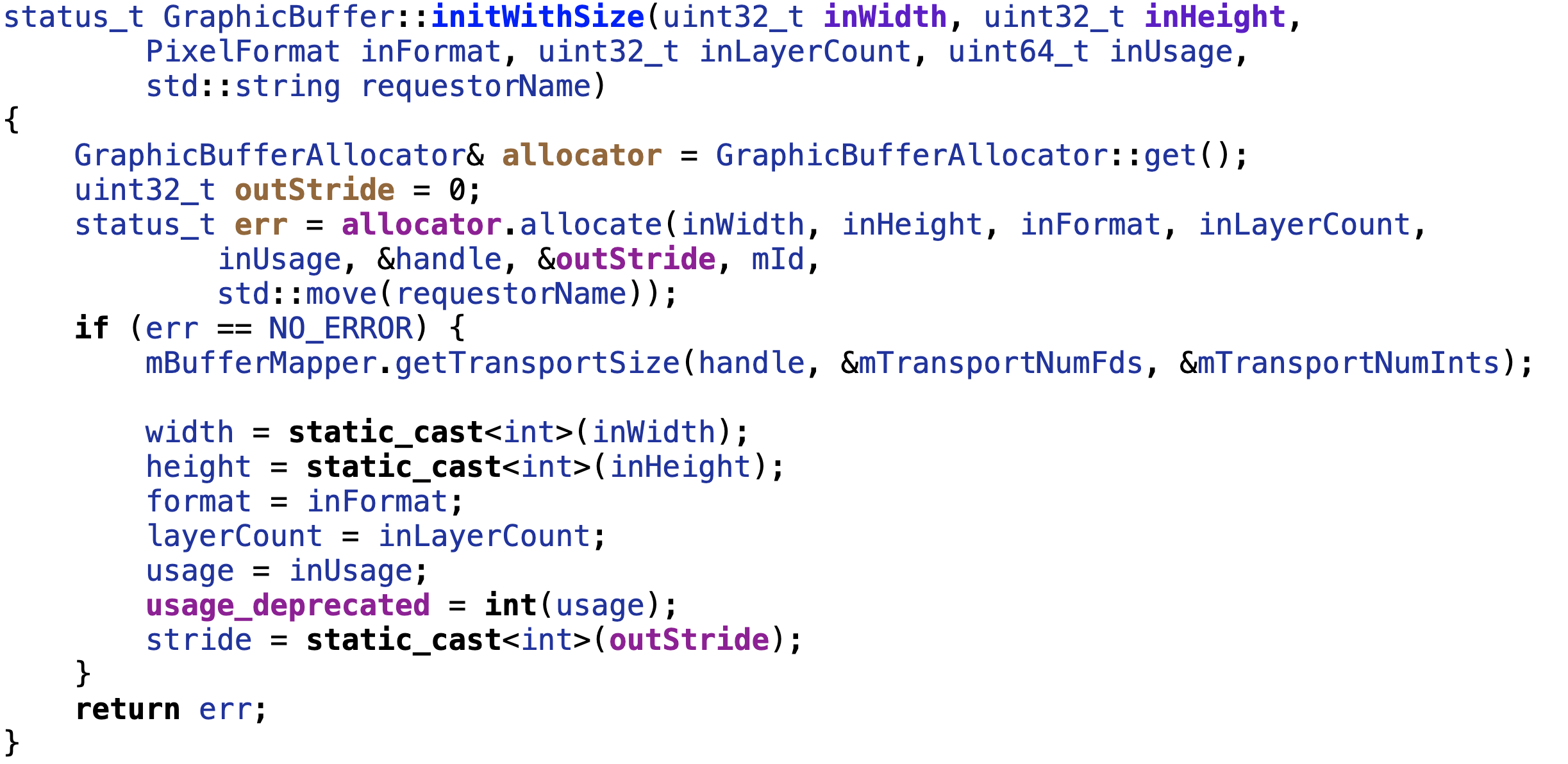 调用gralloc分配缓冲区内存,申请成功后缓冲保存到handle中,使用者得到graphicbuffer对象后取出地址才能保存图形数据。
调用gralloc分配缓冲区内存,申请成功后缓冲保存到handle中,使用者得到graphicbuffer对象后取出地址才能保存图形数据。
status_t GraphicBuffer::lockAsync(uint32_t inUsage, void** vaddr, int fenceFd,
int32_t* outBytesPerPixel, int32_t* outBytesPerStride) {
const Rect lockBounds(width, height);
status_t res =
lockAsync(inUsage, lockBounds, vaddr, fenceFd, outBytesPerPixel, outBytesPerStride);
return res;
}
status_t GraphicBuffer::lockAsync(uint32_t inUsage, const Rect& rect, void** vaddr, int fenceFd,
int32_t* outBytesPerPixel, int32_t* outBytesPerStride) {
return lockAsync(inUsage, inUsage, rect, vaddr, fenceFd, outBytesPerPixel, outBytesPerStride);
}
status_t GraphicBuffer::lockAsync(uint64_t inProducerUsage, uint64_t inConsumerUsage,
const Rect& rect, void** vaddr, int fenceFd,
int32_t* outBytesPerPixel, int32_t* outBytesPerStride) {
auto result = getBufferMapper().lock(handle, usage, rect, base::unique_fd{fenceFd});
if (!result.has_value()) {
return result.error().asStatus();
}
auto value = result.value();
*vaddr = value.address;
if (outBytesPerPixel) {
*outBytesPerPixel = legacyBpp != -1 ? legacyBpp : value.bytesPerPixel;
}
if (outBytesPerStride) {
*outBytesPerStride = legacyBps != -1 ? legacyBps : value.bytesPerStride;
}
return OK;
}
graphicbuffer保存了图形缓冲的文件描述符handle,对文件描述符进行mmap操作可得到图形缓冲的内存地址。
应用程序调用graphicbuffer的lockasync可以获取缓冲的内存地址。应用程序得到地址后可以向图形缓冲读,写图形数据。
hardware composer
1.合成图形:把多个图形缓冲传给硬件混合渲染器,通知硬件混合渲染器执行合成操作。
2.显示图形:把图形缓冲直接显示到屏幕。
3.上报事件:接收底层上报的事件并转发给客户进程。 IComposer 主要用于客户端进程与hwc进程建立通信连接。
/**
* Creates a client of the composer. All resources created by the client
* are owned by the client and are only visible to the client.
*
* There can only be one client at any time.
*
* @return error is NONE upon success. Otherwise,
* NO_RESOURCES when no more client can be created currently.
* @return client is the newly created client.
*/
@entry
@callflow(next="*")
createClient() generates (Error error, IComposerClient client);
createClient用于创建IComposerCliet对象,IComposer对象由HIDL_FETCH_ICoomposer创建
extern "C" IMapper* HIDL_FETCH_IMapper(const char* /*name*/) {
return GrallocLoader::load();
}
class HwcLoader {
public:
static IComposer* load() {
const hw_module_t* module = loadModule();
if (!module) {
return nullptr;
}
auto hal = createHalWithAdapter(module);
if (!hal) {
return nullptr;
}
return createComposer(std::move(hal));
}
加载模块;
创建适配层对象:hwchalimpl
创建IComposer对象:负责创建IComposerClient对象并返回给客户进程。 IComposerClient 每个客户对象对应一个屏幕
interface IComposerClient {
@entry
@callflow(next="*")
registerCallback(IComposerCallback callback);
@callflow(next="*")
createLayer(Display display,
uint32_t bufferSlotCount)
generates (Error error,
Layer layer);
}
注册回调,客户端可以接收hwc进程的事件。
interface IComposerCallback {
@callflow(next="*")
onHotplug(Display display, Connection connected);
@callflow(next="*")
oneway onRefresh(Display display);
@callflow(next="*")
oneway onVsync(Display display, int64_t timestamp);
}
onHotplug:当前显示设备插入或者移除时,通知客户端进程
onrefresh:通知客户进程提供新的帧缓冲
onVsync:向客户进程发送Vsync信号
客户端进程通过composer与hwc进程通信
Composer {
mComposer = IComposer.getservice(servicename);
mComposer->createclient()
}
getservice得到IComposer对象。然后创建IComposerClinet对象保存到mClient中。
Composer通过mClinet与hwc进程建立通信连接。
硬件混合渲染器合成
客户进程需要把图形缓冲传给hwc进程,在由hwc进程传给显示驱动,通知硬件混合渲染器合成图像,合成好后直接传给显示设备。需要有3个步骤
1.创建图层
客户进程把图形缓冲传给hwc进程,首先需要创建涂层。
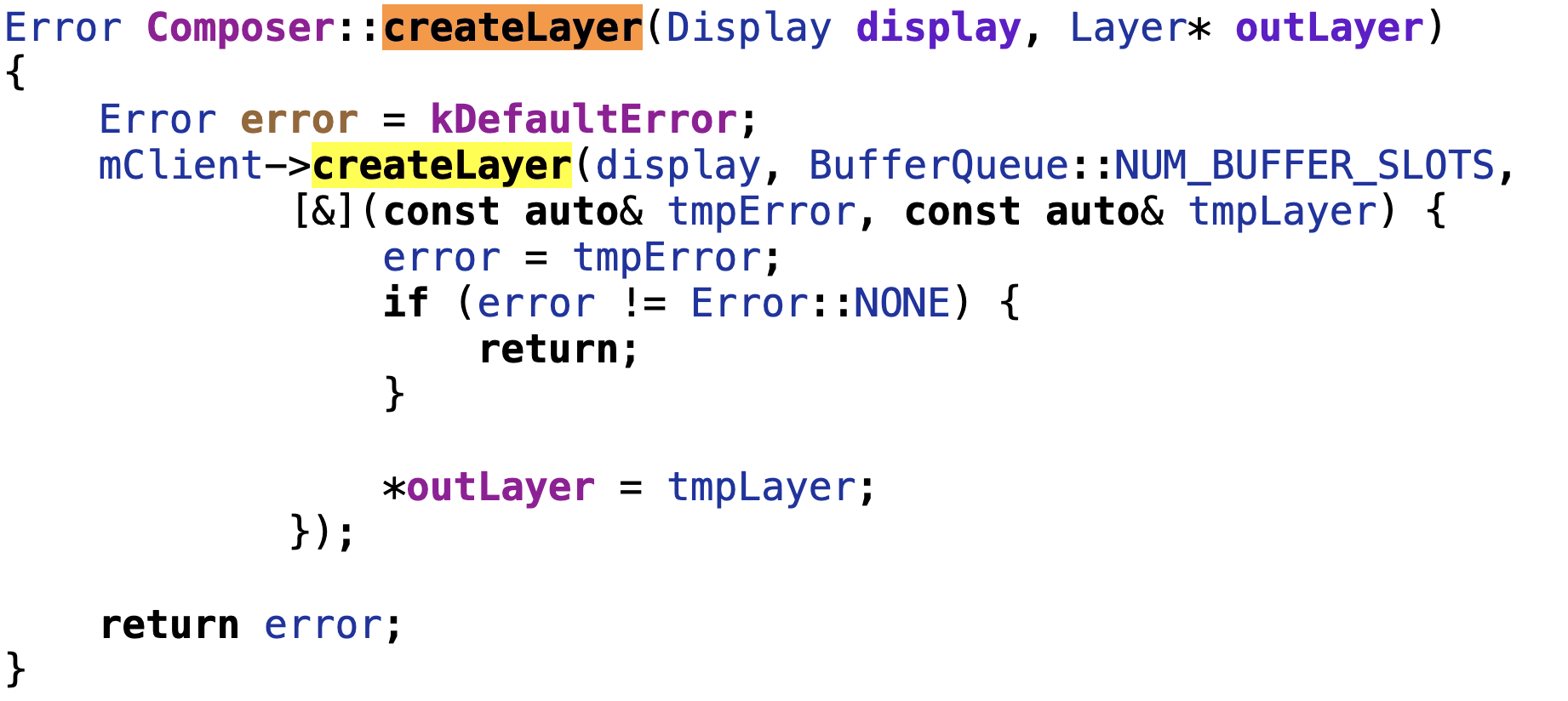 向hwc进程请求创建图层
向hwc进程请求创建图层
ComposerClientImpl收到请求后转给适配层对象hwchalmpl处理。
hwchalimpl收到请求后交给设备对象处理。
hwcsession继承hwc2_device_t,收到createlayer后交给hwcdisplay处理
 将创建的图层存放到layer_map中。
2.设置图层缓冲
设置好了图层后,客户端将图形缓冲传到hwc进程。composer的setlayerbuffer用于向hwc进程传递客户端进程的图形缓冲
将创建的图层存放到layer_map中。
2.设置图层缓冲
设置好了图层后,客户端将图形缓冲传到hwc进程。composer的setlayerbuffer用于向hwc进程传递客户端进程的图形缓冲
 其中取出graphicbuffer的handle。把handle传到hwc进程。
其中取出graphicbuffer的handle。把handle传到hwc进程。
hwclayer处理setlayerbuffer
HWC2::Error HWCLayer::SetLayerBuffer(buffer_handle_t buffer, int32_t acquire_fence) {
if (acquire_fence == 0) {
DLOGE("acquire_fence is zero");
return HWC2::Error::BadParameter;
}
const private_handle_t *handle = static_cast<const private_handle_t *>(buffer);
layer_buffer->format = format;
layer_buffer->width = UINT32(aligned_width);
layer_buffer->height = UINT32(aligned_height);
layer_buffer->unaligned_width = UINT32(handle->unaligned_width);
layer_buffer->unaligned_height = UINT32(handle->unaligned_height);
layer_buffer->planes[0].fd = ion_fd_;
layer_buffer->planes[0].offset = handle->offset;
layer_buffer->planes[0].stride = UINT32(handle->width);
layer_buffer->acquire_fence_fd = acquire_fence;
layer_buffer->size = handle->size;
layer_buffer->buffer_id = reinterpret_cast<uint64_t>(handle);
return HWC2::Error::None;
}
此时已经将图形缓冲的数据发送给了hwc 合成并显示 hwcdevice收到commit请求后把图层缓冲数据给到驱动。
DisplayError HWDevice::Commit(HWLayers *hw_layers) {
DTRACE_SCOPED();
HWLayersInfo &hw_layer_info = hw_layers->info;
Sys::ioctl_(device_fd_, INT(MSMFB_ATOMIC_COMMIT)
}
图形库合成
合成图形的工作也可以由客户端完成,客户端进程通过图形库合成图形的得到帧缓冲,通过hwc将帧缓冲传给显示驱动。
 显示帧缓冲
hwc的hwc2onfbadapter收到请求后,调用framebuffer的fb_post将帧缓冲传递到显示驱动上
显示帧缓冲
hwc的hwc2onfbadapter收到请求后,调用framebuffer的fb_post将帧缓冲传递到显示驱动上
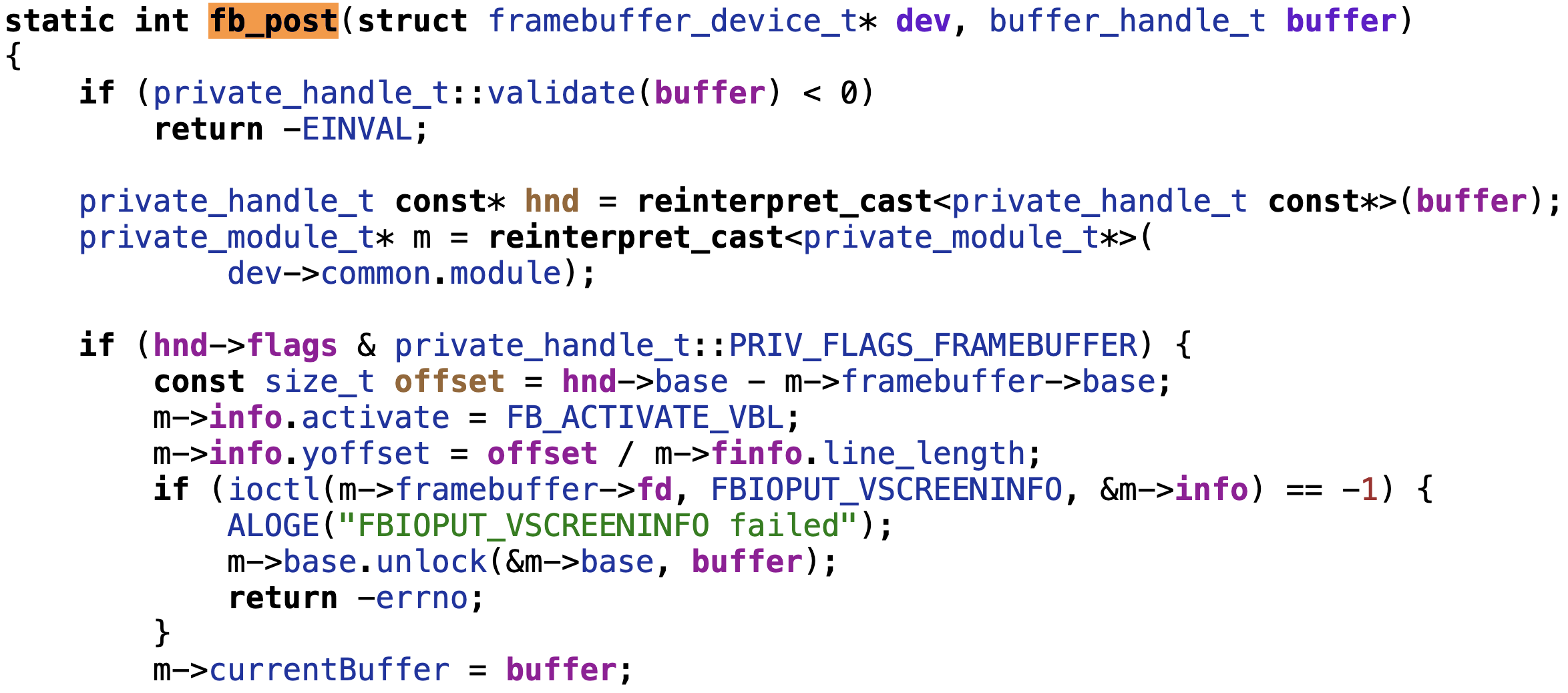 通过ioctl将帧缓冲传递到显示驱动,显示驱动收到帧缓冲会把它传给显示设备。
通过ioctl将帧缓冲传递到显示驱动,显示驱动收到帧缓冲会把它传给显示设备。